Resumé
Hvad er digital kunsthistorie? Dette nyudnævnte felt adresserer en bred mangfoldighed af metodiske, kunstneriske, teoretiske og historiske undersøgelser, hvor computeren bliver inddraget i processen. Samtidig bliver tusindvis af kulturgenstande i disse år registreret med metadata og fotografier, hvilket giver et nyt grundlag for visuelle analyser for både menneske og maskine. Artiklens ærinde er at give en indgang til feltet med afsæt i artiklens case; en visuel analyse ved hjælp af kunstig intelligens af digitale værkfotografier fra SMK – Statens Museum for Kunst. Desuden forklares en række emner og begreber, som har betydning for arbejdet med visuelle problemstillinger på det digitale felt. Et argument i artiklen er, at de digitale metoder og de konkrete eksperimenter med det kunsthistoriske materiale kan motivere et kritisk genbesøg af de kunsthistoriske arbejdsprocesser.
Artikel
Visuelle problemstillinger på det digitale felt er længe blevet adresseret af computerspecialister og kunstnere samt i det digitale humaniora, hvor mange forskellige fagligheder arbejder med et visuelt materiale. Allerede i firserne blev mødet mellem kunsthistorie og computer diskuteret, og gruppen CHArt (Computers and the History of Art) blev dannet. Siden hen har kunsthistorikere samt mange andre fagligheder specialiseret sig i det voksende genstandsfelt af computerbaseret kunst og kulturfænomener. Ikke desto mindre er det først for nylig, at kunsthistoriefagligheden har fået en mere omfattende, målrettet indsats i etableringen af feltet digital kunsthistorie (digital art history), hvor kunsthistorien i sin bredde bliver adresseret.1 Det betyder bl.a., at man tillige studier i digital samtidskunst og medieteori også arbejder med at udvikle studier i ældre perioders kunst og kultur metodisk, teoretisk og didaktisk ved hjælp af computeren. Så selvom kunsthistorikere også tidligere har arbejdet med digital kunst og medieteori, er det først nu, at teknologien og computerkræfterne er tilgængelige og udviklede nok til, at de kan få en mere gennemgribende effekt på kunsthistoriefaget.
Denne artikel består af 1) en introduktion til aspekter af feltet digital kunsthistorie, 2) en præsentation af et digitalt eksperiment med fotografier af kulturarv og 3) afsnit, der introducerer til tekniske begreber og billedproblematikker på det digitale felt samt 4) en perspektivering. De tekniske afsnit kommer i sidste del af artiklen, selvom vi har overvejet, hvorvidt de skulle være præsenteret tidligere i stedet. Men da teksten er rettet til kunsthistorikere uden særlige forudsætninger inden for feltet, har vi valgt at tilstræbe et tilgængeligt sprog, som så senere udbygges med forklaringer af et mere teknisk tilsnit. Samtidig er det intentionen, at analysen af det digitale eksperiments visualisering kan fungere som en generator til at få generelle forklaringer og aktuelle problemstillinger frem.
I slutnoterne findes henvisninger til en bred vifte af litteratur, diskussioner og forskellige typer af projekter inden for digital kunsthistorie, og det er således artiklens ærinde at bidrage med eksempler og refleksioner, som forhåbentligt kan inspirere flere til at engagere sig i at udvikle den kunsthistoriske faglighed i samspil med digital teknologi.
Digital kunsthistorie
Betegnelsen digital kunsthistorie har således siden årene omkring 2010 rammesat feltet. Kurser, sommerskoler og arbejdsgrupper er blevet etableret, og i 2015 blev et internationalt tidsskrift dedikeret til feltet, mens andre tidsskrifter som det amerikanske tidsskrift Panorama i år udvider deres redaktion med en digital kunsthistorieafdeling.2 ’Digital kunsthistorie’ bliver anvendt som et paraplybegreb, der forbinder en række aktiviteter inden for kunsthistorisk undervisning, kuratering og forskning, hvor man i mere eller mindre omfattende grad anvender digitale redskaber og metoder. Denne brede definition af digital kunsthistorie inkluderer således alt fra at etablere billeddatabaser og anvende PowerPoint i en kunsthistorisk forelæsning til at anvende kunstig intelligens i en visuel analyse af digitale billeder. Men, som den ofte citerede digitale humanist og kunstner Johanna Drucker indvender, kan man bryde feltet ned i to overordnede områder, hvor man skelner imellem ’digitaliseret kunsthistorie’ (digitized art history) og ’digital kunsthistorie’ (digital art history). Digitaliseret kunsthistorie omfatter f.eks. opbygning af digital infrastruktur såsom digitalisering af arkiver og billeder, og begrebet beskriver kunsthistoriens generelle skifte fra analoge til digitale redskaber og platforme. Digital kunsthistorie definerer Drucker derimod mere snævert som studier af kunst og kultur, hvor man anvender computational processing i analyseprocesserne af det digitaliserede eller digitale kunsthistoriske materiale.3 I praksis betyder det, at digital kunsthistorie i denne forstand handler om at anvende computerkræfter såsom kunstig intelligens til at analysere et digitalt skriftligt eller visuelt materiale, hvortil der hører refleksioner over teori og metode. Denne skelnen korresponderer med den differentiering af digital humaniora, Jan Luhmann og Manuel Burghardt refererer til som digitized humanities og numerical humanities (anvendelse af computationelle modeller), hvortil der kan lægges betegnelsen humanities of the digital (studiet af digitale fænomener, f.eks. online kommunikation) og feltet public humanities i et digitalt perspektiv.4
Man har længe været i gang med digitaliseringsprocesser til gavn for kunsthistoriefaget, mens man først de seneste år for alvor er begyndt at se på, hvordan man kan involvere computeren i selve analysearbejdet f.eks. billedanalytisk og overveje, hvilken betydning det kan få for fagets udvikling og metoderepertoire. Som Drucker formulerer formålet med digital kunsthistorie: “We have to take into account the ways digital humanities more broadly have taken up computational techniques and then consider the specificity of visual art objects and their particular requirements and points of resistance.”5
En af de tidlige finansieringskilder til digital kunsthistorie, The Getty Foundation, definerer åbent og heuristisk feltet således: “The term ‘digital art history’ has become a shorthand reference for the potentially transformative effect that digital technologies hold for the discipline of art history.”6 Men hvordan skal den ’transformerende effekt’ forstås? Kritikerne af digital kunsthistorie fremfører, at selvom en del redskaber er blevet digitale, så er de kernefaglige aktiviteter og metoder i kunsthistorien stadig grundlæggende set upåvirkede af computational methods, der stadig lader meget tilbage at ønske.7 Det er vi umiddelbart enige i, men alene dét at tage stilling til de teknologiske muligheder, og hvorledes de kan eller ikke kan integreres i den kunsthistoriske forskning, kan flytte på forståelsen af faget og dens metoder generelt.
Vores udgangspunkt er, at kunsthistorie og digital kunsthistorie ikke er modsætninger, men at der i arbejdet med kunst og visuel kultur er en stor variation af forskningsspørgsmål, der kan løses på tværs af digitale såvel som analoge arbejdsmetoder. Som det også kan ses i denne artikels eksempler, så fletter digitale og analoge arbejdsprocesser sig sammen. For at man som fagperson kan navigere i muligheder, træffe konstruktive valg i relation til de enkelte opgaveløsninger og skubbe på udviklingen, er man nødt til at kunne begrunde både til- og fravalg. Men det kræver også viden og erfaringer, som kan give blik for de latente muligheder, digitalt såvel som analogt.
Billeddokumentation af kulturarv, som denne artikels case behandler, bliver i stigende grad frigivet fra institutionerne rundt om i verden og brugt til mange forskellige formål af privatpersoner, fagfolk og kunstnere. Samtidskunst samt ældre kunst og visuel kultur befinder sig allerede i høj grad i en digital virkelighed, hvor mange andre fag end kunsthistorie også arbejder med stoffet. Som et fag med en lang tradition for refleksion over billedbrug, -teori og -forståelse er det oplagt, at kunsthistorie er med til at udvikle kritik og øge kvaliteten, når det kunsthistoriske genstandsfelt i bred forstand behandles digitalt.
En støt voksende gruppe af kunsthistorikere primært i udlandet kan selv kode og anvende computermetoder til at analysere kunsthistoriske datasæt f.eks. visuelt eller statistisk. Men færre færdigheder og erfaringer med tværfaglige samarbejder inden for det digitale kan også være tilstrækkeligt i forhold til at iværksætte kritik og refleksion over, hvad det betyder at inddrage computeren i det videnskabelige arbejde. På denne baggrund introducerer nærværende artikel udvalgte aspekter af forskningsfeltet digital kunsthistorie med eksempler på, hvordan fagets kernefærdighed, den visuelle analyse, kan udfolde sig på det digitale felt. Vi har udvalgt forhold, som er nyttige at være opmærksomme på, når man får computeren til at analysere billeder af kunst og kulturgenstande dokumenteret bl.a. af museerne. Og vi skitserer i grove træk, hvordan computerens billedanalyse foregår. Det åbne spørgsmål er, om den større grad af procesbevidsthed, som arbejdet med at integrere computeren ofte medfører, kan bidrage til, at kunsthistorie udvikler sig metodisk, med eller uden et digitalt element. Den kritiske refleksion over inddragelsen af computeren i den kunsthistoriske forskning er et vigtigt emne, men denne artikel bidrager i højere grad til at opbygge forudsætninger for at gå ind i feltet fremfor at udfolde den kritiske dimension.
Dansk digital kunsthistorie?
I USA har store fonde lagt midler til digitalt orienterede projekter inden for humaniora, hvilket har skubbet til udviklingen af centre for digital humaniora, hvor kunsthistoriefaget også har fået plads. I den nederlandske forskning har man længe foretaget statistiske undersøgelser, geomapping og socioøkonomiske analyser af kunst og kultur bl.a. fra den tidlig moderne periode, og disse studier har fået en digital dimension.8 Andre landes tradition for empiriske studier og arkivstudier, f.eks. i de tysktalende områder, giver dem gode forudsætninger for at omsætte analog informationsindsamling til digitale formater, der kan danne grundlaget for computerbaserede analyser.9
Nu er det kunsthistoriske forskningslandskab meget større i både Nederlandene, USA og Tyskland, hvor forskningsgrupper og -infrastrukturer giver flere muligheder. På de to danske kunsthistorieenheder på universiteterne arbejder man i mindre grad med omfattende genstands- og kildestudier eller digitaliseringsprocesser, som kræver en større organisering og adgang til kulturarven. Selvom dette er en generalisering, har man her oftere en orientering mod forskningsspørgsmål, der primært baseres på æstetiske, filosofiske og teoretiske tilgange og arbejdsmetoder. Med mindre man arbejder med emner som computerkunst eller medieteori, kan det derfor være mindre entydigt eller åbenlyst, hvordan man kan operationalisere f.eks. et filosofisk orienteret spørgsmål og identificere enheder, der kan omsættes og bearbejdes af computeren på relevante måder. Det kræver ikke kun teknisk udvikling men også et tænkearbejde at finde ud af, hvordan computeren kan være med til behandle ord eller billeder. Hvordan vil man f.eks. kunne inddrage computeren, hvis man vil arbejde med atmosfærebegrebet i forhold til museumsarkitektur? Eller hvordan kan computeren bidrage til at undersøge, hvordan æstetiske principper tager form sprogligt eller visuelt i bestemte historiske miljøer? Selvom der findes eksempler på disse typer af projekter, vil materialet og forskningsspørgsmålene kræve idéudvikling både teknisk og metodisk, og der er færre erfaringer på feltet at trække på.10 Det kræver altså en indsats at identificere, hvor (og om) computeren kan bidrage fyldestgørende, og om computeren allerede har en model, der kan bruges som f.eks. objektgenkendelse, semantisk analyse af ord eller netværksanalyse af et skriftligt eller visuelt materiale. Dernæst er spørgsmålet, om der findes et datasæt, der er afgrænset, annoteret og digitaliseret. Her har man f.eks. arbejdet med billeddatasæt såsom kunstauktionskataloger fra 1800-tallet, middelalderlige, religiøse motiver, portrætfotografier eller forsider af modemagasiner.
I de danske kulturinstitutioner og forskningsmiljøer findes der datasæt, potentielle datasæt og forskningsspørgsmål, som vil kunne drage nytte af digitale metoder på forskellig vis. Men før computerspecialister kan involveres, kræver det, at kunsthistorikeren på det konceptuelle plan har en fornemmelse af de betingelser, computeren giver, og det er som sagt disse forudsætninger, denne artikel bidrager til opbygningen af.
Projektet bag artiklen
I projektet bag denne artikel undersøges det, hvorledes udvalgte computermetoder kan anvendes i den kunsthistoriske forskning, samtidig med at fagets dybe billedteoretiske tradition kan aktualiseres og anvendes til at stimulere refleksion over billedbrug og -begreber i det digitale humaniora.11
Et grundlæggende greb er, at vi udvikler de teoretiske aspekter i udveksling med digitale forsøg, således at projektet får en praksisdimension, som øger idéudviklingen og refleksionsdybden. Analysematerialet er digitale værkfotografier, der er produceret og bearbejdet på forskellige måder, og det har motiveret os til at udvikle begreberne det udvidede og det reducerede værk. Netop for at informere definitionerne af begreber som disse udføres visualiseringer på baggrund af digitale eksperimenter med fotografier af kulturarv. Medieringsprocesserne af værkernes materialitet spiller en væsentlig rolle, og den visuelle analyse som metode er et omdrejningspunkt for studierne. Senere i denne artikel illustreres ’det reducerede værk’ med et enkelt eksempel, hvor kunstig intelligens har bidraget til en visuel analyse af tusindvis af værkfotografier. Projektet tager således udgangspunkt i Druckers sidstnævnte definition af digital kunsthistorie, hvor computeren bliver inddraget som en slags analytisk medspiller. Dermed handler denne artikel såvel som projektet ikke om selve digitaliseringsprocessen af kunst og kulturgenstande, etablering af digitale infrastrukturer i museumsinstitutionen, FAIR-principperne eller bestræbelserne på open access.12 Eller for den sags skyld om studiet af digitalt baseret kunst eller computerkunst, som også bliver opfattet som en del af digital kunsthistorie.
Det digitale billede – det reducerede værk
Relationerne mellem kulturgenstand, dets dokumentation og datavisualisering er vigtige men også vanskelige diskussionsemner, som har fået øget relevans pga. den teknologiske udvikling. Man kan således i stigende grad indsamle, optage og digitalt opbevare og bearbejde forskellige typer dokumentation om genstandene, herunder digitale billeder. Det er samtidig et stående spørgsmål, hvilken information der skal prioriteres og registreres i de enkelte sager, og hvordan informationerne skal repræsenteres og fortolkes, særligt i et videnskabeligt øjemed. For en del kulturarvsprojekter har den digitale fotodokumentation en afgørende betydning både for projektets design og for, hvorvidt man kan fortolke det datasæt, man har indsamlet.13 På et mere basalt niveau handler det også om, at fotografiet i sig selv er en fortolkning, der skal tages stilling til.
Selvom det er en dyd i kunsthistoriestudierne at have førstehåndskendskab til værker og værkgrupper, har man nu såvel som tidligere ofte tilegnet sig et værkkendskab ved hjælp af reproduktioner. Kunsthistoriker Christopher Lakey giver et eksempel på, at fotografiske reproduktioner har ledt til mulige fejlfortolkninger i kunsthistorieforskningen. I sit studie af fotografering af relieffer fra senmiddelalderen får han vist, at fotograferingsvinklen har haft afgørende betydning for, hvordan man i kunsthistorien har fortolket stil og udtryk. Reliefferne er fotograferet lige forfra, og motiverne fremstår derfor statiske og livløse, hvilket fik betydning for beskrivelsen af stilen. Hvis man i stedet anskuer reliefferne fra den tiltænkte beskuerposition skråt neden for værkerne, får de et helt andet dynamisk udtryk.14 I et digitalt perspektiv har sagen om ”the yellow milkmaid” skabt fokus på, at de digitale fotografier af kunstværker, som er i omløb, kan forvrænge folks forestillinger om, hvordan et værk ser ud.15 Europeana satte i 2011 fokus på det, der siden er blevet kaldt ”The Yellow Milkmaid Syndrome”, hvilket adresserer erkendelsen af, at rigtig mange fotografier af kunst og kultur af meget ringe kvalitet er i omløb på internettet, herunder Johannes Vermeers (1632-1675) maleri af en mælkepige. Denne erkendelse har været medvirkende til at øge museernes bestræbelser på, at professionelle og autoriserede fotografier er tilgængelige for offentligheden.
På et andet niveau må man konstatere, at uanset hvor højopløselig, velbelyst og fintunet fotografiet er, vil det altid kun gengive et begrænset udvalg af værkets fysiske karaktertræk. Dette vilkår begrænser på forskellig vis, hvad billederne kan anvendes til i en digital databehandling, hvis relationen til det afbillede værk er relevant i den enkelte analyse. Fotografiet formidler værkets tilsynekomst i ét koreograferet øjeblik, og fotografiet vil altid allerede være en reduceret version af det remedierede værk, én blandt mange fremstillingsmuligheder. Denne basale kunsthistoriske indsigt er ikke en naturlig del af refleksionerne, når værkfotografier anvendes i computeranalyser, og i det hele taget spiller kunsthistoriens kritiske tradition for billedanalyse og -teori ofte en meget lille rolle i andre fags anvendelse af disse fotografier på det digitale felt.
Ved at kalde de digitale værkfotografier for reducerede værker ønsker vi at øge opmærksomheden på fotografiet som mediering, hvor kun et udsnit af genstandens materialitet og virkemidler gengives i hvert enkelt billede, digitalt som analogt.16 Det kan desuden tilføjes, at den digitale databehandling yderligere reducerer fotooptagelsen af værket i oversættelsen fra lysinput til tal.
Reproduktioner kan både få et liv i sig selv og øge interessen for værkerne, men i denne sammenhæng er udgangspunktet, at de digitale eksperimenter i en eller anden grad skal give noget til forståelsen af SMK – Statens Museum for Kunsts samling, også selvom det foregår ved hjælp af reproduktioner. Det er altså ikke ligegyldigt, hvor meget det enkelte værk bliver reduceret i medieringen, og relationen mellem værk og reproduktion er stadig relevant. Værkets remedierede versioner udspalter og frasorterer træk ved værkerne, men computerens billedanalyse kan potentielt set anskueliggøre uerkendte eller usynlige aspekter for det menneskelige øje, om det så er relevant for kunsthistorieforskningen eller ej. Samtidig kan både reduktioner og udvidelser af værket i den digitale dimension fremme en opmærksomhed på, hvad der tabes og vindes i processen visuelt og materielt.
Kvantitativ billedanalyse
Man har efterhånden så store mængder af digitaliserede oplysninger om kunst- og kulturgenstande, at det kan give mening at få computeren til at udpege strukturer i materialet, både det visuelle og det tekstuelle. I denne artikels case er billedmaterialet analyseret kvantitativt af computeren. Kort sagt anvendes algoritmernes visuelle analyse på et stort billedmateriale og fremstilles derefter i en visualisering, som kan tilgås via en browser. Denne kvantitative tilgang til billedanalyse er blevet kaldt ’distant viewing’ som en visuel pendant til litteraturteoretiker Franco Morettis begreb om ’distant reading’, hvor ords forekomster og strukturer i meget store tekstmængder analyseres ved hjælp af algoritmer.17 Computerspecialist og kulturanalytiker Lev Manovich er hyppigt citeret for at være en af de første til at foretage konkrete ’distant viewing’-analyser og producere de karakteristiske datavisualiseringer, hvor tusindvis af billeder er vist med små ikoner samlet i en skyformation – på samme måde som det gøres i nærværende digitale eksperiment.18 Men hvor Manovich arbejder med fotografier fra sociale medier og de kulturelle sfærer, som disse billeder opererer inden for, tager denne artikels case udgangspunkt i værkfotografier, der er knyttet til andre sociale praksisser og koder defineret bl.a. af museumsinstitutionen og dens dokumentationstradition.
SMK’s billeddatasæt var ikke optimalt i forhold til computeranalyse, hvor man gerne vil identificere visuelle slægtskaber mellem de afbillede værker. Det gælder for en hel del institutioner, at deres datamateriale er præget af institutionens dokumentationspraksis og dens forandringer igennem årtier. I SMK’s digitaliserede værksamling kan man se udviklingen fra sort-hvide fotooptagelser til farvefotografi og digitale billeder i standardiseret belysning samt en vekslende grad af tilkoblet tekstbaseret metadata. Som i alt andet arbejde med empiri, så sætter billeddokumentationens ukurante sammensætning derfor rammerne for, hvad man kan bruge materialet til i en videnskabelig proces.
Kend din samling
Hvis man vil kende et museums samling og enkelte genstande, vil man typisk besøge museet eller læse udstillingskataloger og forskningslitteratur samt søge i databasen og studere hjemmesiden. Kun i særlige tilfælde vil man kunne se ting i magasinerne. I både litteraturen og udstillingsrum vises ofte kun en brøkdel af samlingen, og man får i formidlingsmaterialet kun et indtryk af et mindre udsnit, oftest de mest kendte værker. Selvom man i dag arbejder på alternative adgange til museets onlinesamling, vil man ofte på museets hjemmeside møde værkgengivelser via databasen, hvor man i visningen kun vil kunne se mindre portioner ad gangen.19 Som format giver billedskyen en anden type navigation end databasehjemmesiden, og dermed får man en mere direkte adgang til et bredere udsnit af samlingen, og den kan give en anden form for overblik over den digitaliserede del af samlingen: dens komposition og tyngdepunkter. Den mindre kendte kunst kan komme til syne, og rent visuelt tegner skyen et billede af de større linjer. F.eks. falder det i øjnene, hvor stort omfanget af papirværker er på SMK, og så er det endda stadig kun en mindre del af de samlede papirværker, som i dag er registreret med fotografi.20 Selvom man kan argumentere for, at man bør lave billedskyer med et relativt homogent materiale – f.eks. kun fotografier af malerier – da man ellers giver computeren en upræcis opgave, så kan en visualisering af SMK’s samlede billeddatasæt netop synliggøre og formidle, hvor bredspektret og sammensat samlingen er. Dette træk kan bl.a. pege tilbage på de mange forskellige samlere, der historisk set har bidraget til samlingen, samtidig med at det kan perspektivere institutionen som museum i dag. Begrænsningen ligger naturligvis i, at værker, der endnu ikke er registreret med ord og billeder, ikke kan indgå i computerens analyser, og derfor vil der være huller i det indtryk, som en billedsky eller en semantisk analyse vil kunne give.
Billedskyens måde at give adgang til billedmaterialet stiller dog også krav til brugeren. At billederne principielt set er lige tilgængelige gør ikke adgangen til dem mere demokratisk. Billedskyen kan fremstå uoverskuelig, opak og labyrintisk, og man kan få oplevelsen af, at det er svært at finde noget interessant – både for lægfolk og kunsthistoriske fagpersoner. Mulighederne for at få noget ud af visualiseringer som billedskyen er stadigvæk betingede og begrænsede af den enkelte brugers forudsætninger og vilkår.21 Måske netop for at imødekomme behovet for at finde en vej igennem billedmængden har Google lagt en slags guidet tour ind i nogle af deres visualiseringer af værkfotografier, mens andre arbejder med mere kontekstinddragende brugerflader såsom VIKUS viewer.22
Googles visualiseringer er typisk konglomerater af værkfotografier fra mange forskellige samlinger, mens det digitale eksperiment, vi foretog, er et abstraheret billede af et enkelt museums digitaliserede del af samlingen. Det kan give mening at se på computerens analyse af én samling, men der er også perspektiver i at få visualiseret strukturer og forekomster på tværs af samlinger.23
Digitalt forsøg med ca. 40.000 værkfotografier
I det følgende præsenteres det digitale forsøg med SMK’s ca. 40.000 fotografier af værker fra samlingen.24 Forsøget med fotografierne fra SMK tog udgangspunkt i software kaldet PixPlot, som er udviklet af Yale University’s digitale center, Yale Digital Humanities Lab.25 Selve datavisualiseringen PixPlot – SMK blev udført af Center for Humanities Computing Aarhus, og i denne artikel adresseres den første version af visualiseringen.26
PixPlot blev udviklet i 2017 og var inspireret af det indflydelsesrige paper ”Visual Patterns Discovery in Large Databases of Paintings”, som blev fremlagt ved Digital Humanities Kraków i 2016.27 Dengang formåede man at få kunstig intelligens i form af et såkaldt convolutional neural network (CNN) til at visualisere strukturer i databasebilleder af malerier, og i forhold til ydeevne er denne såkaldte deep learning stadig anerkendt som en af de mest effektive metoder til at studere billeddatasæt. Yale Digital Humanities Lab byggede videre på denne måde at analysere store mængder af fotografier, men de anvendte i stedet det mere sofistikerede CNN-netværk Inception V3, som var blevet udviklet til fri brug hovedsageligt af folk fra Google.28 Med PixPlot formåede de yderligere at få komprimeret computerens resultater, så de kunne udtrykkes i en todimensionel interaktiv visualisering. Sigtet var at få produceret et redskab til at udforske store samlinger af digitaliseret billeddata. Den første PixPlot-visualisering er lavet på baggrund af et datasæt på ca. 27.000 primært ældre digitaliserede fotografier fra Beinecke Rare Book & Manuscript Library, og flere andre samlinger på Yale er blevet visualiseret med succes, herunder Yale Centre for British Art og The Medical History Library. På den måde har PixPlot været med til at udfolde denne type visualisering i et bredt felt af billeder.
En del andre har også benyttet sig af PixPlot som et eksplorativt redskab til at udforske billeddatasæt af kulturarv. To eksempler er delt på PixPlots side på platformen Github. I det første eksempel bruges PixPlot til at visualisere 24.026 fotografier fra dagspressen Bain News Service i årene ca. 1910-1912, mens man i det andet eksempel bruger 31.097 fotografier fra forskellige norske kulturinstitutioner formidlet på hjemmesiden oslobilder.no. Det tyske forskningsprojekt Training the Archive har også anvendt PixPlot, og her er det særligt de kuratoriske muligheder, man søger at udforske med visualiseringerne.29
Selvom der findes andre modeller som VGG16, ResNet50 og Xception, var PixPlot oplagt at anvende i vores eksperiment, bl.a. fordi Inception V3, som PixPlot er baseret på, er anerkendt for at være en god model til at klassificere billeder. PixPlot er desuden gennemtestet, og modellen er relativt hurtig at sætte i anvendelse. Visualiseringens brugerflade er desuden interaktiv, visuelt appellerende og enkel at anvende. Selvom andre modeller kunne have givet andre visuelle konstellationer af datasættet, så har det ikke været intentionen at studere disse nuancer. Hvis man ønsker nye variationer af visualiseringen, ville det give mere mening i stedet at justere og bygge om på PixPlot – SMK. Kunsthistorikere skal have disse redskaber mellem hænderne og lære dem at kende for at kunne identificere faglige behov, som computeren måske ville kunne udfylde. I den proces kan det blive relevant med tilpasninger eller valg af andre modeller, især da de teknologiske muligheder hele tiden udvikles.
Formålet med at analysere en stor mængde værkfotografier med computeren var at undersøge, hvordan den ville gruppere fotografierne og dermed definere deres visuelle ligheder og relationer. I PixPlot – SMK var det ikke foruddefineret, hvilke billeder der var beslægtede visuelt, og computeren dannede selv de kategorier af billeder, den vurderede havde ligheder. Metadata om værkerne såsom kunstnernavn og årstal var ikke i denne omgang en del af computerens analyse.
Første skridt var at få svar på nogle generelle spørgsmål bl.a. ved at analysere visualiseringen visuelt og sidenhen at øge spørgsmålenes kompleksitet, indtil billedskyen ville skulle revideres for at kunne besvare dem, f.eks. ved at lægge yderligere informationslag til computeranalysen.
Vores første spørgsmål handlede således om, hvorvidt det var muligt at skitsere nogle af de visuelle træk, der var afgørende for computerens sortering af værkerne. Dvs. det drejede sig om at se på visualiseringen som et resultat af computerens handlinger og undersøge, hvad der har været udslagsgivende for de enkelte gruppers dannelse. Kan de karakteriseres, og kan man evt. finde eksempler, der har været vanskelige for computeren at placere på baggrund af dette? Sorterer computeren billederne anderledes, end man typisk ville gøre som menneske? Kan computerens svar på, hvad visuel lighed i kunstværker kan være inspirere os i arbejdet med kunsten og samtidig gøre os klogere på algoritmernes processer? Det er en almindelig strategi på computerfeltet at undersøge slutresultatet af de relativt lukkede computeranalyser for at få indsigt i, hvordan man kan arbejde videre med algoritmerne. Men der foretages sjældent nærmere visuelle analyser af makrovisualiseringer af fotografier af kunst- og kulturgenstande i forskningslitteraturen.
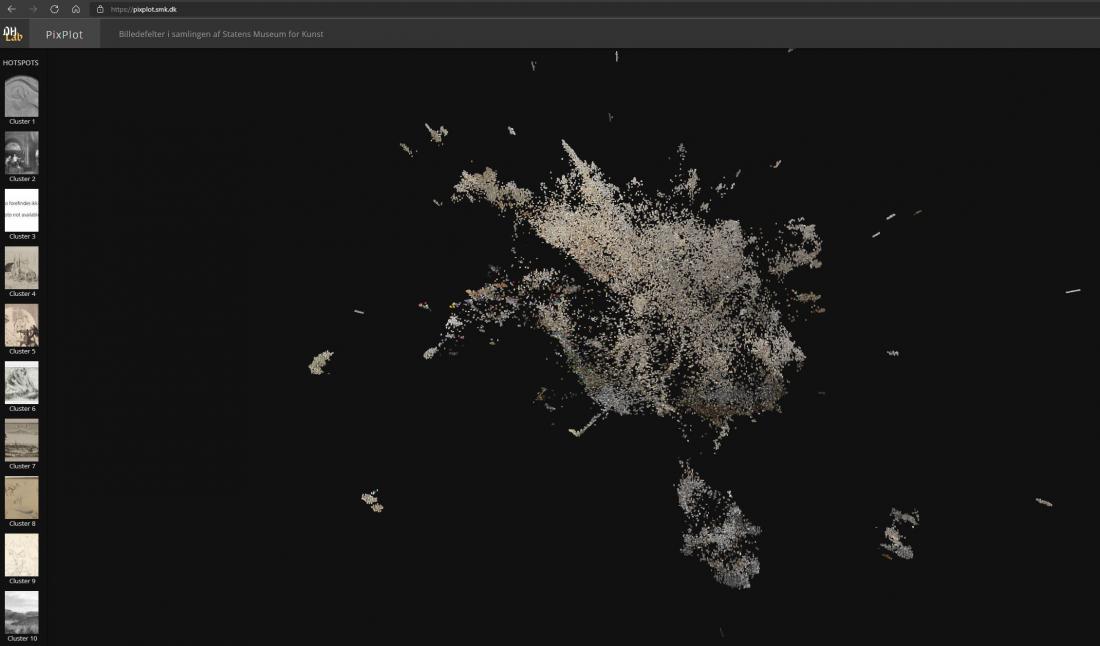
Datavisualiseringen SMK – PixPlot som genstand for visuel analyse
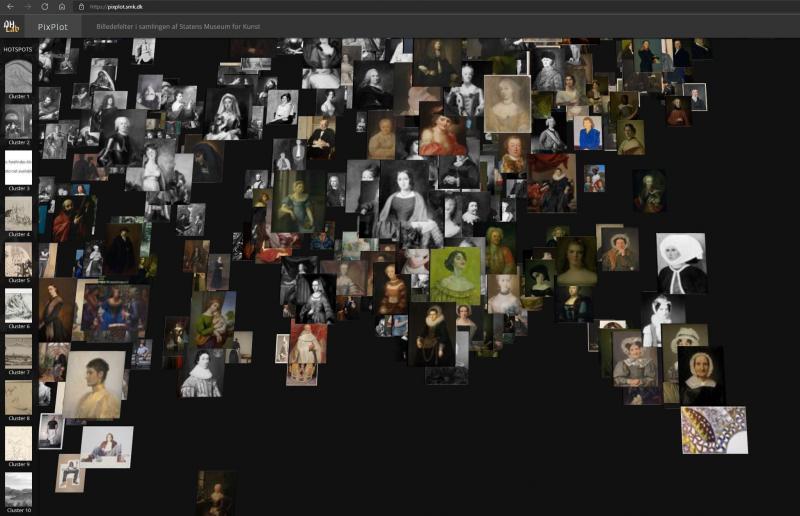
En af kunsthistorikerens basale færdigheder er den visuelle analyse og evnen til at fortolke og kontekstualisere visuelle fænomener. Som analysegenstand udgør PixPlot-visualiseringen af værkfotografier en udfordring, for hvad er det, man skal sætte ord på? Visualiseringen, der ligner en sky dannet af billeder, består af tusindvis af værkfotografier med hver deres visuelle udtryk [Fig. 1]. Skyens figuration består af de enkelte fotografier, som er placeret i nærheden af andre fotografier, computeren har vurderet, at de visuelt hører sammen med. Hvor de enkelte fotografier peger tilbage på værkernes myriader af kunstneriske intentioner, kontekster og budskaber, er selve billedskyen maskinproduceret, og den fremstår uforklaret i sit udtryk. Den ser ud til at være uden intentioner, og oplysninger om valgene bag skyens komposition er begrænsede. Desuden kan tekniske fejl i kodningen også slå igennem og afgøre dele af skyens figuration – og her kræver det en computerspecialist at gennemskue fejlene, både i koden og i interfacet.
Som sagt ovenfor gengives SMK’s 40.000 værkfotografier som thumbnails i en skyformation, som har en lille dybde. Dybden gør, at man kan se de stakke, som billederne er stablet i, når computeren har vurderet dem til at være meget ens. Skyen fortætter omkring midten, og en række arme og øer strækker sig ud fra tyngdepunkterne. Billederne er som tidligere nævnt distribueret i såkaldte klynger (clusters) alt efter computerens bedømmelse af deres visuelle slægtskaber. Disse klynger oplistes med en billedrække i venstre side af interfacet, hvor hver klynge vises med et eksemplarisk billede valgt af computeren. De enkelte klynger er nummererede, men de har ikke automatisk en indholdsbeskrivelse eller en såkaldt label. Den skal tilføjes manuelt.
De følgende analyseafsnit præsenterer udvalgte analytiske vinkler, som man kan anvende generelt, og giver nogle bud på, hvad man som minimum bør undersøge i denne type makrovisualisering.30
Navigation
Samlet set havde vi i analysen af billedskyen en tendens til se efter mønstre og ligheder mellem billeder, samtidig med at netop de ting, der skilte sig ud, fangede vores opmærksomhed. Det havde den konsekvens, at vi på skift fik øje på det, vi nedenfor har kaldt overgange, outsidere og tyngdepunkter. Det kan give mening at være bevidst om, hvilket af disse aspekter, man gerne vil undersøge. Det kan desuden give mening at gennemgå og analysere den tidligere nævnte række af klynger defineret af computeren. Ved at studere værkfotografiernes kendetegn og relationerne mellem dem analyseres også tegn på computerens handlinger og grundene dertil.
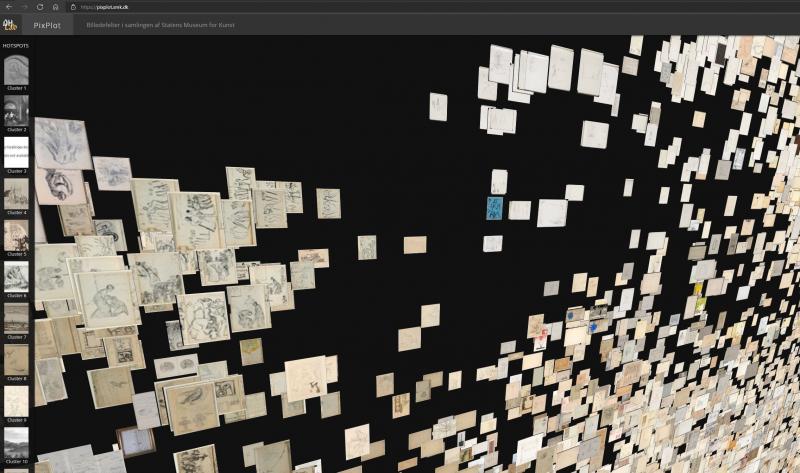
Undervejs i analysen begyndte vi at få en fornemmelse af billedskyens sammensætning og komposition, hvilket gjorde, at vi efterhånden blev bedre til at forudsige, hvilken gruppe et bestemt værkfotografi ville kunne findes i. Vi efterprøvede dette ved at udvælge værker i databasen for derefter at forsøge at finde dem i skyen. Dette kunne lade sig gøre, så længe billederne ikke var en del af de store uklart definerede beigefarvede grupper. Her vil det kræve studier af detaljerne for at finde lighederne, men helt generelt har computeren ofte vanskeligere ved at analysere stregtegning end f.eks. maleri. Fotografiernes overlap vanskeliggør også nærstudier af de enkelte gruppers indhold.31

Form, farve og sort-hvid
SMK’s fotodokumentation består, som sagt, af både sort-hvide fotografier og farvefotografier, og en stor andel af dem gengiver papirværker, som er i lyse beige nuancer. I forbindelse med PixPlot-forsøget var vi interesserede i at se, hvorvidt computeren ville foretage det simple greb at grovsortere efter farveskala og sort-hvide reproduktioner. Netop dette slår igennem i Yale’s PixPlot-visualisering af en samling af primært sort-hvide fotografier fra 1800-tallet, hvor fotopapirets grundtoner i kølig grå og gullighvid dominerer computerens sortering i to store hovedgrupper.32 Det betyder, at andre mulige slægtskaber i undergrupperne i princippet ville kunne blive vægtet lavere og derfor blive splittet op på hver side af den overordnede sortering. Det kan være uhensigtsmæssigt alt efter, hvilket formål visualiseringen tjener. Grundtonen i papiret kan være en relevant sorteringsfaktor, hvis man undersøger distribution eller proveniens. Her er spørgsmålet så, om PixPlot er præcist nok som redskab. Det kan altså være relevant at undersøge, hvilke vægtninger de enkelte visuelle træk ser ud til at have, og hvilke konsekvenser det kan indebære.
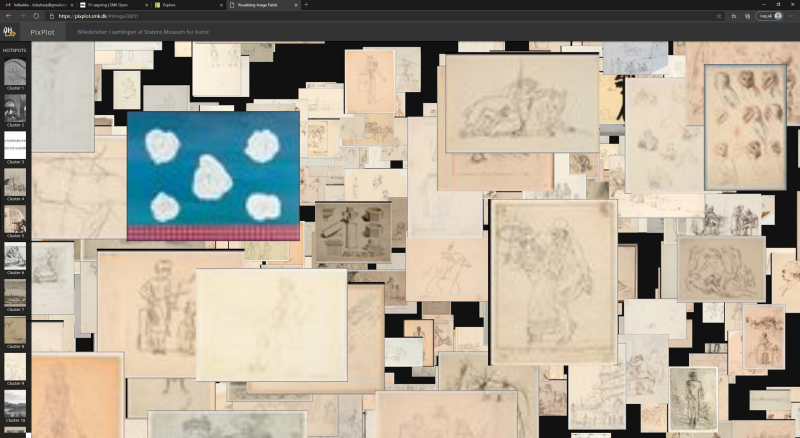

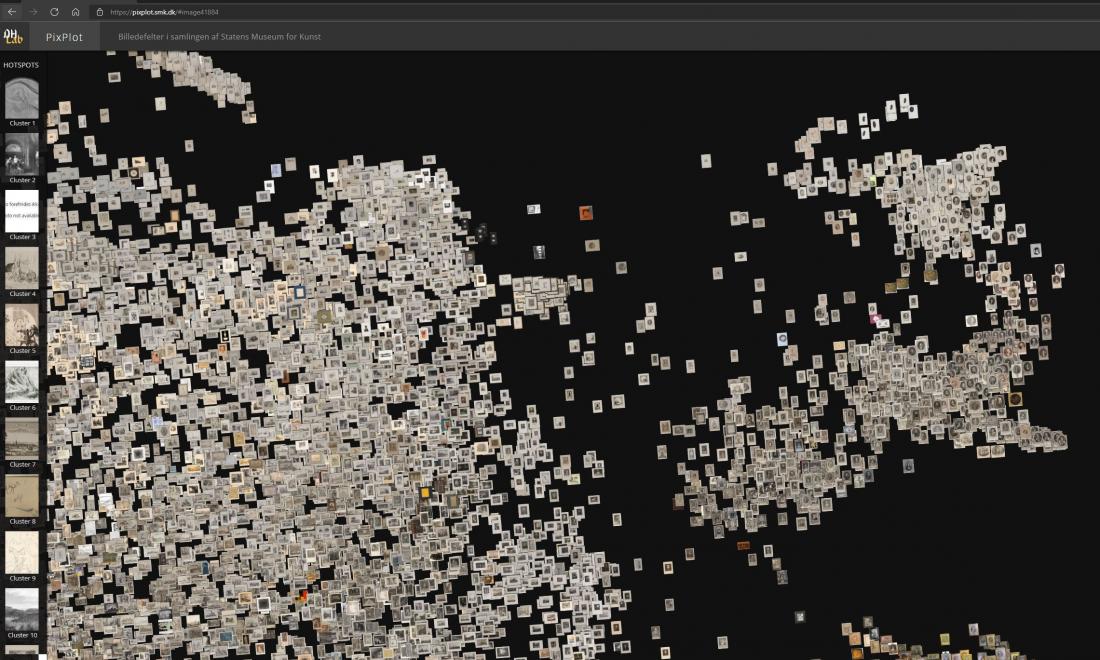
I PixPlot-visualiseringen af SMK-billederne dominerer de lyse papirværker med store sammenhængende grupper, men ved nærmere eftersyn viste det sig, at de mangfoldige motivers kompleksitet og kompositioner var ligeså afgørende træk i sorteringen som værkfotoets grundtonalitet. En stor gruppe af fotografier af maleri er f.eks. blevet samlet i visualiseringen, selvom de er gengivet i både sort-hvid og farve. Det tyder på, at kompositionernes karakter frem for farven har været en afgørende faktor i computerens analyse [Fig. 2]. Der er flere eksempler på, at stærkt farvede værker skiller sig ud fra de omkringliggende lyse papirværker [Fig. 3a, 3b, 3c]. Her er det måske den simple komposition, der trækker det farvede billede ind i klyngen. I et andet eksempel ser det ud til, at en firkantet form i billedet afgør dets placering nærmere end dets farve og kontraster [Fig. 4]. Renæssancens dyst mellem farve og form som det vigtigste parameter i udtrykket gentager sig altså i det digitale.
Af andre eksempler på makrovisualiseringer af værkfotografier, hvor farven spiller en markant rolle, har Google Arts & Culture Experiment foretaget nogle af de mest omfattende. Ved hjælp af avanceret maskinlæring har de lavet to visualiseringseksperimenter med værkfotografier, Curator Table og t-SNE Map, begge med en tydelig farvesortering.33 I Curator Table danner billederne tilsammen en firkant med et udstrakt bakket landskab, mens t-SNE har en åben kant og en mere ujævn distribution. Begge viser værkerne fordelt i plamager af farvetoner. På nært hold er der tydelige undergrupper, f.eks. smykker fotograferet mod en sort baggrund eller blåmalet porcelæn, hvor farven som sorteringsparameter er tydelig. Til gengæld er det vanskeligt at gennemskue en del af overgangene mellem farveplamagerne. F.eks. er det ofte ikke tydeligt, om der er visuelle forbindelser i motiv eller former mellem en gruppe af mørke billeder og en tilgrænsende gruppe af lyse billeder. Har computeren identificeret de to grupper hver for sig, og er det blot tilfældigt, at de to grupper derefter ender ved siden af hinanden i selve visualiseringen? I andre eksempler på overgange er der andre tydelige formmæssige ligheder, f.eks. kan man finde cirkulære former på tværs af farveskift.
Farvesortering kan være hjælpsomt, hvis man leder efter nogle bestemte værker – især hvis de er i en kraftig farve. I andre tilfælde vil det være mere nyttigt at kunne se strukturer på tværs af farverne og dermed nedbryde deres dominans og få andre visuelle træk til at vægte mere.34 Under alle omstændigheder er det ofte relevant at overveje, hvordan vægtningen mellem form- og farvetræk skal være, når man træner sine algoritmer ud fra et bestemt formål.
Rammer
Rammen – og rammegivende træk som passepartout, facon og randdekorationer – markerer typisk periferi og grænse til omverdenen for værker som maleri, tegning og grafik. I kunsthistorien er disse træk ofte blevet opfattet som værende af sekundær værdi, mens de vægtige betydningsbærende elementer er at finde i motivet, som typisk er placeret centralt. Computeren er i sin visuelle analyse derimod ofte mere optaget af rammegivende visuelle træk end det, som vi anser for at være hovedmotivet. Dvs. at et ovalt motiv eller et hvidt passepartout ofte vil blive det definerende træk for billedet i computerens analyse, uanset hvad motivet end er.
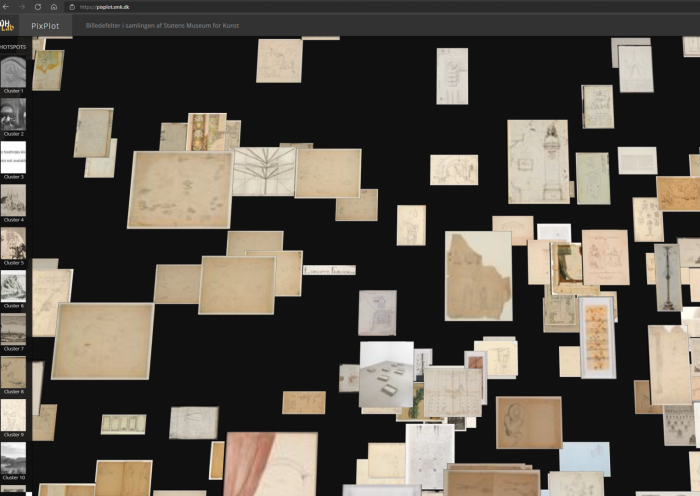
En af opgaverne i dag er således ikke kun at få algoritmerne til at genkende strukturer og mønstre og sortere efter dem, men også at få dem til at ignorere visuelle formelle træk, som man kan finde uinteressante at sortere efter. Det kan i denne sammenhæng tilføjes, at fotografier af tredimensionelle genstande som bøger og skulpturer i PixPlot – SMK kan ende i klynger med rammelignende træk, da omgivelserne muligvis tolkes som passepartout eller rammer [Fig. 5]. I andre udsnit af billedskyen vægtes motivet højere end tydelige rammegivende træk. F.eks. er et portræt placeret i portrætgruppen, selvom guldrammen ligeså vel kunne have sendt det over i gruppen af billeder, hvor rammen er fællestrækket uanset motiv. Et andet sted samler en gruppe af fotografier af tegnede portrætter sig om det fællestræk, at de vender på hovedet. Det gør, at de ikke bliver grupperede med beslægtede portrætter, der vender rigtigt. Dette illustrerer, at computeren her ikke er blevet gjort bekendt med konventioner, som hjælper mennesket i dets behandling af billederne. Hvis man til gengæld beder computeren om at korrigere specifikke fejl, som man har fundet i datasættet, f.eks. at fjerne guldrammer, der ikke skulle have været med, eller at vende portrætter om, kan den – når først koden er skrevet – typisk udføre manøvren langt hurtigere og på et større materiale, end mennesket kan.
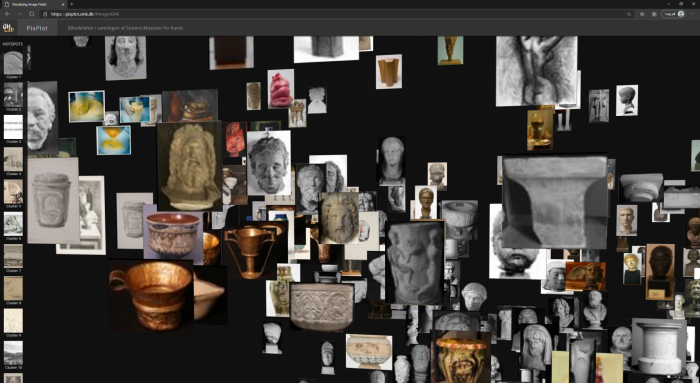
Tredimensionelle genstande
I billedskyen finder vi et sort-hvidt fotografi af en døbefont. Den minder os om, at fotografiet kan være både værket i samlingen og midlet til at registrere værket. For computeren er der ingen forskel, og på flere måder kræver fotografi af tredimensionelle genstande mere omtanke, når man bruger dem som datasæt, især hvis man vil inddrage dem i rene visuelle computeranalyser som denne, hvor metadata ikke spiller en rolle. Værker som maleri og grafik er også tredimensionelle og materielle genstande, hvor mange træk udelades, f.eks. bagsider, kanter og overfladens struktur, men i fotografering af værker som skulpturer eller installationer bliver problematikken endnu mere markant. Der er som oftest ikke én vinkel på værkerne, som kan indfange hele motivet eller værkets dimensioner. Omgivelserne vil ofte komme med i fotografiet, og valget af vinkel, beskæring og omgivelser kan ændre radikalt på billedets formelle træk og komposition. Det bliver dermed uklart, hvad computeren egentligt er sat til at analysere i forhold til billedet og det gengivne værk. Hvis man derimod vil undersøge en værkfotograferingsstil og dens ændringer over en tidsperiode, f.eks. affotograferinger af Bertel Thorvaldsens (1770-1844) skulpturer, er opgaven så klart defineret, at computerens visuelle analyse godt kan give mening.35 Her bliver selve fotografiet og dets formelle logik med andre ord fokus for analysen frem for det afbillede værk i sig selv. Dette eksempel illustrerer, at det er nødvendigt at afprøve men også at lade sig inspirere af de teknologiske redskaber for i en gensidig udveksling at tilpasse redskab og forskningsspørgsmål.
Fotografier af skulpturer og installationer er i PixPlot – SMK relativt ofte blevet placeret blandt andre værkfotografier, som de i en vis grad ligner. Det gælder f.eks. fotografiet af installationen Eight-Part-Piece af Robert Smithson (1938-1973), hvor det med sine lyse beige farver og geometriske former ligner papirværkerne, som omgiver fotografiet i PixPlot-visualiseringen [Fig. 6]. Men særligt en række fotografier af installationen Ritual II af Tonny Hørning (f. 1941), en kirkeinteriørlignende installation, bliver af computeren dømt så partikulære, at de ender i en isoleret gruppe [Fig. 7]. Dette undrede os, da fotografierne ligeså vel kunne være placeret iblandt de grafiske værker med deres enkle geometriske former og brun-beige kontraster. Her slår det muligvis igennem, at netværket er oplært med billeder fra ImageNet, hvor kirker og kirkeinteriør optræder. Det kan betyde, at netværket genkender installationens lighed med dette emne og derfor etablerer en særskilt klynge til dem trods de visuelle ligheder med grafiske værker. Hvis man havde behov for at få computeren til at skelne mellem kirkeinteriør og gallerirum, ville man i princippet kunne oplære netværket med et træningssæt, hvor de visuelle forskelle mellem de to rumtyper er manuelt definerede (supervised learning, se senere). Spørgsmålet er da, om gallerirummet kan defineres visuelt stærkt nok til, at definitionen ville samle installationer og andre tredimensionelle genstande inklusiv Hørnings værkfotografier. Hvorvidt man kan etablere et sæt af visuelle markører, der er klart nok for computeren, er en af de overvejelser, man bør gøre sig, hvis man vil fintune et netværk til at foretage sorteringer ud fra specifikke visuelle kriterier. Men det er også her, der er potentiale for, at computeren kan overraske og f.eks. fremhæve eller koble værker på tankevækkende måder.
Outsidere
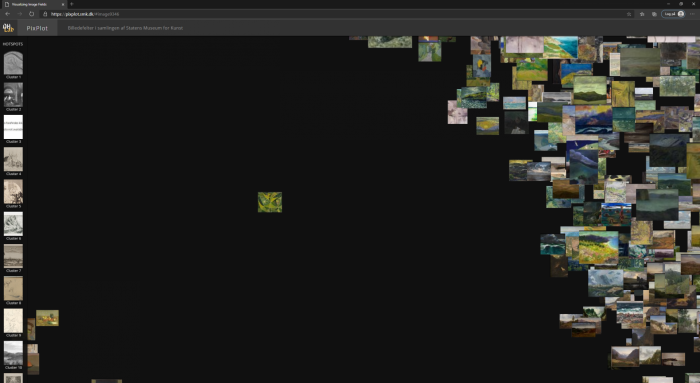
Som de to eksempler ovenfor illustrerer, kan outsidere både findes inde i grupper og være ensomme billeder, der ligger langt fra de andre. Og nogle outsidere kan virkelig undre. F.eks. ligger det grønne værk Kosmisk landskab af Egill Jacobsen (1910-1998) helt alene ud for gruppen af landskaber, som det ifølge computeren ikke er visuelt tæt nok på til at blive en del af – uden at det dog ender i en af de non-figurative grupper eller trækkes tæt på andre grønne værkfotografier [Fig. 8]. Muligvis ligner Jacobsens billede også genstandsopstillingerne, som er den nærmeste gruppe i den modsatte retning. Kunne det tyde på, at billedet i computerens analyse er spændt op imellem to visuelle tyngdepunkter, der trækker i hver sin retning og efterlader billedet hængende alene? Eller er billedet virkelig så særligt, at det ikke bør have nære naboer?
Outsiderne, både de integrerede og de ensomme, kan til tider bruges af computerspecialisten til at identificere fejl i koden. I andre tilfælde kan outsiderne bruges til at oplære netværket i en bestemt retning og dermed fungere som en nøgle til at justere analyseprocessen. Ved at give systemet feedback på dets valg kan man øge en træfsikkerhed, som man samtidig definerer. På den måde vil man kunne gennemføre analysen igen og ændre på skyens komposition og fremme nuancer i computerens analyse. F.eks. kan computeren trænes til at genkende en kunstners stil og dermed i princippet kunne samle vedkommendes værker i skyen trods forskelligt motiv. I en anden type opgave har man trænet algoritmerne til at genkende strukturer i malerier af Frans Hals (c. 1582-1666) for dernæst at anvende det oplærte netværk til at detektere områder i et udvalgt maleri, hvor andre hænder end Hals har været involveret i malearbejdet.36 Set fra denne vinkel er ingen kategoriseringer fejlagtige, før man definerer, hvad der er en fejl. Her er det igen relevant at overveje, hvilke ligheder og forskelle der er mellem mennesket og maskinens måde at analysere billederne på. Og hvorvidt man ønsker at vejlede computeren i bestemt retning, f.eks. at den skal genkende en stilart eller et bestemt motiv. Dvs. at den skal lære at mime den menneskelige billedgenkendelse og sorteringstradition. I forhold til selvkørende bilers navigation er det en vigtig ambition at efterligne den menneskelige genkendelse af genstande via billeder. I forlængelse af connoisseurship-traditionen har man i den såkaldte tekniske kunsthistorie og konserveringsfaget nået milepæle ved at supplere den menneskelige evne til at studere ligheder og forskelle i værkernes visuelle og fysiske strukturer med teknologien.37 Hvis computeren kan opnå den status at blive en optimeret analysemakker på flere måder, vil det kunne få betydning for dele af kunsthistoriefagets arbejdsgange.
Spørgsmålet er da, om det ville være et større nybrud, hvis computeren kunne udfordre os og give os alternative analyser af materialet i stedet, som kunne blive relevante for os som mennesker. F.eks. kunne vi få relativeret vores forståelse af, hvad visuelt slægtskab mellem billeder kan være. Eller uerkendte sammenhænge i vores billedkultur kunne blive synlige. Måske kan computerens forstærkende effekter på iboende værdidomme bragt med via træningssættet endda tydeliggøre aspekter af vores kultur, som vi bør tage op til overvejelse, f.eks. at vi har ubevidste visuelle udtryk for misogyni eller racisme. Set fra en anden vinkel handler computerens arbejde med billeder også om, hvordan dens analyser spiller ind i vores samfund – ofte uden at billedet bliver synligt. Set fra dette perspektiv, har kunstnere længe arbejdet med de sociale aspekter af menneske/maskine-interaktionen og de muligheder, der ligger i feltet for at udvikle værker med æstetiske og kritiske agendaer.38 I denne artikels sammenhæng er det relevant, at computerens alternative måder at arbejde med kulturarvsdokumentationen med tiden måske vil kunne rykke ved nogle af de grundlæggende hierarkier i kunsthistorien: Hvilke værker er vigtigst for vores kultur? Hvilke værdier hviler de kunsthistoriske værdidomme på? Hvilket kunst- eller kulturbegreb arbejder den enkelte kulturinstitution med? På den måde vil man også kunne synliggøre de konstruerede grænser mellem visuel/materiel kultur og de klassiske kunstarter som maleri, tegning, skulptur og arkitektur.
En helt enkel faktor, som allerede er tydelig i PixPlot – SMK, er, at computeren kan synliggøre værker og grupper af værker, som ellers ikke får opmærksomhed. Hvis man i højere grad anvendte denne indgang til samlingerne og fik et større kendskab til den mindre behandlede og anerkendte empiri, ville det potentielt set kunne rykke ved fagets interessefelter og hierarkier. Som vi kommer ind på senere, handler dette også om implicitte og måske ubevidste værdidomme, som er en stor diskussion inden for anvendelsen af kunstig intelligens i samfundet generelt.

Overgange og tyngdepunkter
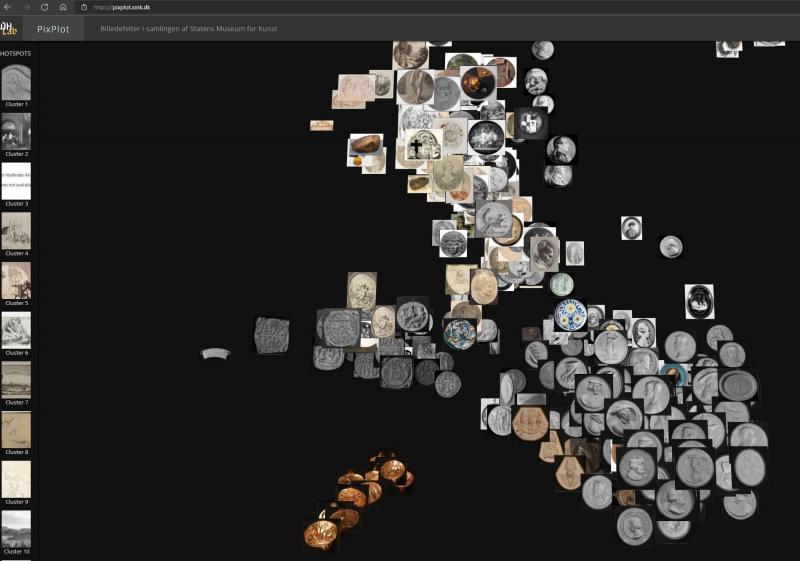
Et andet analytisk perspektiv på billedskyen drejer sig om at identificere og undersøge tyngdepunkter og overgange imellem grupperne. Tyngdepunkter af relativt ens billeder bliver i en vis grad defineret af de grupper, der illustreres i bjælken til venstre i interfacet (cluster 1 – 20), men mange undergrupper kommer ikke frem dér. Buster og værker med cirkulær komposition er meget tydeligt samlet i hver sin gruppe, men her er måden, genstandene er fotograferet på, også relativt ensartet [Fig. 9a, 9b]. En del fotografier af tredimensionelle genstande grupperes også sammen, på trods af at de formelt set er meget forskellige [Fig. 10].
De gradvise overgange i skyen kan være relevante at studere, hvis man har store grupper af meget ensartet materiale. Det kan give et indtryk af varianter af ligedannede visuelle træk og motivkategorier. I de store papirværksgrupper fandt vi f.eks. to overgange, hvor den ene overgang spændte fra en løs-urolig penneføring til en mere kontrolleret og tyndere streg, mens den anden overgang gik fra indrammede værker til værker med hvidt passepartout. Vi fandt desuden en del andre typer af overgange, der var motivisk betingede. F.eks. er der en overgang fra nøgne til påklædte menneskekroppe og en anden overgang fra menneskekroppe til slagtekødsmotiver samt et skifte i farvenuancer mellem lyse ensartede fotografier. Et sted ender en stribe af portrætter i et billede uden menneskefigur men med et kniplingslignende mønster [Fig. 11]. Det kan muligvis pege tilbage på, at personerne i portrætterne er iklædt forskellige typer af flæser og kniplinger. Her destilleres et enkelt træk måske ud i computerens analyse.
Disse eksempler er letgenkendelige motiver og formelle træk, og når man finder et tyngdepunkt – f.eks. en gruppe af pattedyrsbilleder – kan man også få øje på de eksempler, der ligger strøet rundt omkring et tyngdepunkt, flettet ind i andre motivgrupper. Her bliver det dog også tydeligt, at man kan komme til at læse forbindelser ind, som kan være opstået tilfældigt og derfor ikke er et direkte resultat af computerens analyse. I alle de nævnte grupper findes der undtagelser fra det, man typisk vil se som det definerende træk.39
Tvivl og black box
I de tilfælde, hvor grupperne i PixPlot – SMK var for blandede til, at vi kunne sætte fingeren på fælles træk, dukkede tvivlen op: Er det os, der overfortolker en sammenhæng mellem værker placeret sammen? Er dét, vi ser som sammenhænge, opstået tilfældigt som rester i periferien af omkringliggende tyngdepunkter? Overser vi de visuelle ligheder, som computeren faktisk arbejder med? Tvivlen kan samtidig også smitte af på iagttagelsen af mere oplagte grupperinger, hvor man ellers først var sikker i sin sag. Genkender computeren f.eks., at billedet viser en hest, eller er det helt andre ting, der tilfældigvis får samlet hestebillederne? Grunden til tvivlen er, at vores bud på hvilke visuelle træk, computeren har defineret de enkelte klynger efter, ikke kan aflæses ud fra visualiseringen – den indeholder ikke dokumentation for de enkelte valg. F.eks. virker det åbenlyst, at computeren har brugt den runde form som det definerende træk i fotografierne af mønter, men det vil koste en større teknisk manøvre at få det bekræftet i en eller anden grad. Computerens analyseproces er ikke transparent endnu – nogen kalder den en black box, og man foretager i den sammenhæng ofte kvalificerede gæt. Et andet aspekt er, at visualiseringen også er en fortolkning på det tekniske plan, hvor computeren har komprimeret dens flerdimensionelle sammenligninger af værkfotografiernes ligheder til en visualisering, der kan vises på en skærm i en simuleret tredimensionalitet.40 Som vi kommer ind på senere, er værket godt nok reduceret i fotooptagelsen og omdannet til talværdier, men de enkelte pixels og deres relationer analyseres på helt andre måder, end det menneskelige øje gør.
Datavisualisering som iterativ læringsproces
I arbejdet med PixPlot – SMK tegnede der sig et billede af muligheder for 1) at få overblik over et meget stort billedmateriale, 2) at bidrage til kritisk tænkning og refleksion over billedanalyse og -teori, når computeren er involveret i processerne, 3) at motivere grundlæggende diskussioner om kunsthistoriefeltets metode, empiri og teori og 4) at overveje konsekvenser af ikke-menneskelige blikke på visuelle fænomener. Det er ikke alle aspekter, vi kan runde her, men vi vil kort knytte nogle ord til den procesforståelse, som computeren stimulerer, da vi anser, at en indsats i forhold til denne kompetence kan styrke kunsthistoriefaget generelt.
PixPlot – SMK er ikke udviklet til at løse en bestemt opgave, og vi har endnu ikke formuleret konkrete faglige problemstillinger eller anvendelsesmuligheder på SMK. Generelt er arbejdet med at anvende billedskyer ikke for alvor påbegyndt på feltet, men vi aner konturerne af, at visualiseringer som PixPlot – SMK har potentiale i forbindelse med lærings- og udviklingsprocesser i forskning, kuratering, undervisning og formidling.41
Lavpraktisk kan man som forsker have brug for alternative måder at opbygge hukommelseskort over sin empiri, at anskueliggøre strukturer, man ser, eller at blive provokeret af computerens analyse. Det kan også handle om at bruge datavisualiseringen som udgangspunkt for udviklingen af nye idéer – måske endda sammen med andre, hvor kommunikationen og dét at kunne illustrere sine tanker er vigtige elementer, som visualiseringer kan understøtte. I undervisning vil man f.eks. kunne bruge billedskyen som et greb til at få den studerende til at finde og opbygge fortællinger ud fra værkfotografier. Men også selve det at arbejde med et datasæt og dets visualisering har et lærings- og erkendelsesmæssigt potentiale. Dette er blevet dokumenteret i et konkret undervisningsprojekt, hvor man koblede datalogistuderende med kunsthistoriestuderende. De skulle arbejde med at behandle og visualisere et datasæt om renæssancehumanister, og som Elizabeth Honig et al. i den forbindelse konkluderer: “The shuttle back and forth between quantifiable data and humanistic inquiry through data and its visualization was a hugely fruitful exercise”.42 De iterative processer gav en forståelse af datasæt samt kunstfaglige og tekniske krav, og nogle af de samme erfaringer drog vi i arbejdet med PixPlot – SMK. Set fra kunsthistorikerens side opnår man dermed et grundlag for at gå i dialog med computerspecialisten om, hvordan computeranalyse, datasæt og visualisering skal videreudvikles – eller man får idéen til, hvordan nye datavisualiseringer og forskningsspørgsmål kan udformes.
Vores tilgang til at etablere billedskyen var således eksplorativ og rettet mod refleksion-i-handling.43 Set fra denne vinkel behøver billedskyen og andre digitale eksperimenter m.a.o. ikke at være et resultat i sig selv, men de kan netop være et refleksionsrum eller en trædesten til at nå nye steder hen.
Vores næste skridt er, at PixPlot – SMK skal have yderligere informationslag tilknyttet såsom metadata eller bredere kontekster til værkfotografierne, så den sociale og kulturelle dimension bliver tilgængelig i analysearbejdet.44 PixPlot – SMK skal også kobles med andre samlingers datasæt for at følge konfigurationernes ændringer. Det vil give en anden måde at studere og sammenligne samlingers udvikling f.eks. i de nordiske lande, deres bestanddele og de indsamlingsmønstre, der kommer til udtryk visuelt. Vi skal samtidig have kigget nærmere på de klynger, hvor der allerede er dukket materiale og forbindelser op, som kan bruges i helt andre studier om f.eks. tidlig moderne gengivelser af naturgenstande.
Dernæst er udfordringen, at man i arbejdet med computerens resultater har brug for fleksibilitet i forhold til at interagere med eventuelle visualiseringer, og man kan få brug for løbende at justere på computeranalysen eller datainputtet. Her er man som kunsthistoriker typisk afhængig af andre fagligheder og af, at der bliver udført et ofte tidskrævende manuelt arbejde f.eks. med omskrivning af kode eller digitalisering. På sigt håber vi på, at der kan blive lavet et brugervenligt program, hvor man kan uploade sit billedmateriale og få produceret makrovisualiseringer af forskellig art – uden at man skal have kodefærdigheder.
Digital kunsthistorie udfolder sig mellem flere fagligheder, og hvis man vil engagere sig i feltet, er det nødvendigt i en vis grad at tilegne sig fagterminologi, der hører til computerfaget og digital humaniora. I et digitalt kunsthistorieprojekt skal flere fagligheder ofte samarbejde, og man får brug for at kommunikere om målsætninger, proces og resultater.45 Der er derfor i de følgende afsnit knyttet nogle ord til nogle tekniske begreber, som er relevante i forhold til at forstå computerens visuelle analyse. Undervejs knyttes pointer fra arbejdet med PixPlot – SMK og andre relevante projekter af kunsthistorisk tilsnit.
Computeren som begynder: Læringsproces
Kunstig intelligens eller artificial intelligence (AI) handler om ambitionen om at få computeren til at efterligne (og overgå) menneskets kognitive processer og ræsonnementer f.eks. i et skakspil eller i en dialog. Grundlæggende set består kunstig intelligens af algoritmer, dvs. en sekvens i kodeskrift, der beskriver en række computationelle operationer, som kan behandle et datasæt. Disse algoritmer kan opbygges i de såkaldte kunstige neurale netværk (artificial neural networks) – en betegnelse inspireret af, hvordan man har forklaret de biologiske processer i hjernen. Analyseprocessen foregår i lagene af neuroner, som hver især bedømmer inputtet ud fra forskellige egenskaber. Disse dybere netværk (convolutional eller deep neural networks) kan i stigende grad håndtere komplekse problemstillinger og finde subtile mønstre, som ikke bemærkes i menneskets analyse.46 Af formidlingsmæssige årsager bruger vi her kun termerne computer og algoritmer, da kunstig intelligens er et stort felt med mange applikationsområder og subdomæner, herunder maskinlæring (machine learning) og deep learning.47
Man har længe kunnet sætte computere til klart definerede opgaver, f.eks. ’indstil husets alarm til kl. 19’, men i dag er man optaget af at udnytte algoritmernes evne til at lære og optage erfaringer i mødet med datainput og feedback fra mennesket. Computeren kan med andre ord identificere strukturer i datamaterialet og derfra opstille hypoteser eller regler. F.eks. vil den kunne foreslå et tidspunkt at slå alarmen til alt efter den data, som man giver den om aktiviteter i huset. I forhold til billeder vil algoritmerne eksempelvis kunne lære at genkende et ansigt ved at analysere et stort antal billedeksempler, frem for at man skal give computeren et færdigt sæt regler for, hvordan et ansigt ser ud. På den måde får computeren selv skabt kriterierne for, hvornår ’ansigt’ findes i billedet eller ej, og den vil gradvist kunne blive bedre til det, jo flere eksempler den får. Denne evne til at lære ved hjælp af erfaringer gør det nemmere at justere computerens færdigheder og overføre dem til andre domæner og situationer, i stedet for at man hver gang på ny skal opstille regler for enhver tænkelig situation.48
I denne sammenhæng er det væsentligt at forstå forskellen på, om algoritmernes læringsproces er supervised eller unsupervised, da det siger noget om, hvordan mennesket er involveret i processen.49
Oplæring med eller uden vejledning
Før en computer kan arbejde med et ukendt datasæt, skal den have et træningssæt, hvor den kan lære at genkende, gruppere og definere forskellige typer af forekomster. Sagt med andre ord oplæres algoritmerne med et stort udvalg af eksempler, der ligner det ukendte materiale, den vil kunne møde efterfølgende – de bliver pre-trained. På den måde får man oplært en model, der efterfølgende kan bruges på et nyt datasæt. Da der gerne skal mange tusinde billeder til, før algoritmerne har gjort sig erfaringer nok til at kunne genkende nye eksempler, kommer det kunsthistoriske materiale ofte til kort. Derfor må man typisk tage algoritmer i brug, der er oplært ved hjælp af fotografier af alt muligt i verden, de såkaldte natural images, og dermed er algoritmerne kun i mindre grad oplært på baggrund af fotodokumentation af kunst og kulturgenstande i museernes magasiner.50 Mennesket har desuden bestemt kriterierne for, hvad træningsdatasættet indeholder, og hvordan de enkelte billedelementers labels er definerede, dvs. de betegnelser, som man manuelt har knyttet til hvert enkelt billede i dette datasæt. Her er første mulighed for, at fordomme eller bias kan slå igennem og præge processen.51
Når computeren bliver sat til at klassificere et billede af f.eks. et dyr, vil dens svar typisk være en procentsats. F.eks. kan computeren vurdere, at billedet med 80 % sikkerhed er en hund, men også at det med 20 % sikkerhed er en kamel. I den vejledte læring bliver computeren instrueret og korrigeret i, hvad der er et positivt eller negativt resultat ved hjælp af de definitioner eller labels, mennesket giver den. Hvis et netværk skal lære at afgøre, om et billede viser en golden retriever eller ej, skal det møde en masse annoterede billeder af hunde og andre lignende former. Hvis netværket ikke har mødt en kat før og derfor ikke har lært at skelne mellem hunde og kattes forskellige kendetegn, kan computeren godt vurdere et billede af en gullig kat til f.eks. at være en golden retriever. Det er da fællestræk som farve, ører, pelsstruktur, øjne, snude osv., som slår ud. Hvis man da giver computeren besked om, at kattebilledet ikke er et positivt resultat, vil det bidrage til, at computeren efterhånden lærer at foretage netop denne skelnen mellem gullige katte og retriever-hunde.52 Hvis man f.eks. vil have algoritmerne til at afgøre, hvem der har designet kaffestellet på billedet, men netværket kun er oplært med billeder af jungledyr, er opgaven forkert stillet. Svaret vil sikkert blive, at stellet er en blandet vægtning mellem dyrearter, der ligner stellets farvekombinationer og former. Her bliver det tydeligt, at valget af træningsmateriale og de labels, der gives, betinger de opgaver, man kan få algoritmerne til at løse. Følger man denne tankerække ud i det kunsthistoriske materiale, hvor flertydighed, abstraktion og dialektiske relationer mellem del og helhed kan betinge aflæsning og meningsdannelse, bliver det tydeligt, at man som fagperson skal foretage valg, der kommer til at præge modellen og dens anvendelighed eller mangel på samme.
Når læringsprocessen ikke er superviseret, danner computeren i stedet grupperinger af datasættet ud fra de strukturer, den finder selv (clustering). Den giver så at sige sit bud på, hvilke regler der gælder for datasættet frem for at sortere datainputtene i foruddefinerede kasser som hund, kat, kamel osv. (classification). De unavngivne clusters danner baggrund for en datavisualisering, hvor computeren fremstiller sine resultater.
I denne artikels case analyserer algoritmerne SMK’s værkfotografier unsupervised, dvs. uden at computeren på forhånd har fået faste kategorier, den skal definere værkerne ud fra. Den finder så at sige selv strukturer og forekomster i materialet og etablerer en række grupper ud fra sine analyser. Men som sagt har computeren erfaringer fra et træningssæt af fotografier, og det er derfor forventeligt, at SMK’s værker med f.eks. heste eller ansigter samles i grupper i visualiseringen. Der opstår altså nogle tydelige ikonografiske grupperinger, hvor der dog kan være nogle overraskende bud indimellem som tidligere beskrevet.
Træningssættets betydning
Som sagt påvirker træningssættet algoritmernes færdigheder, hvilket kan illustreres med det berømte eksempel, hvor man fik en computer til at kunne skelne mellem billeder af husky-hunde og ulve. Det blev gjort med stor succes, men det var sneen i baggrunden af ulvebillederne, der var afgørende for computerens konklusioner.53 Dette eksempel er gammelt før dagen er omme, men det er relevante pointer, at computeren ser ud til at være påvirket af det datasæt, den er oplært af, og at den kategoriserer visuelle ligheder på andre måder, end vi typisk vil gøre. Det er som sagt afgørende, hvad algoritmerne er oplært til at kunne bestemme og hvilket materiale, de har gjort sig erfaringer med.
Ligheder og forskelle mellem træningssættet og det datasæt, man vil have computeren til at analysere, har også betydning for, hvad man kan anvende dens analytiske kunnen til i digital kunsthistorie. I dag anvender man som tidligere nævnt typisk algoritmer, der er trænet til at genkende og kategorisere billeder på baggrund af millioner af fotografier af verden omkring os fra det kendte og berygtede datasæt ImageNet.54 Men i kunsthistorieprojekter, hvor man arbejder med computerens visuelle analyse, beder man typisk computeren analysere fotografier af kunst og kulturgenstande, som ofte fungerer visuelt på andre måder end fotografier af verden. Et vedblivende spørgsmål er, hvordan man kan oplære og tilpasse algoritmerne, så de bliver mere brugbare og er mere præcise, når de anvendes på fotografier af kunst og kulturgenstande.
Billedet som tal
Selvom computeren analyserer billeder og identificerer billedelementer, ’ser’ den ingenting men arbejder kun med tal, som definerer hver enkelt pixels egenskaber. Da det er en væsensforskellig proces sammenlignet med den måde, vi som mennesker ser på billeder, knytter vi derfor i det følgende nogle enkelte ord til dens analyseproces.
At digitale billeder teknisk set består af tal er en anden afgørende grund til, at vi kalder de digitale værkgengivelser for reducerede værker. De digitale fotografier kommer til syne for os som billeder på skærmen, men computeren arbejder med dem som tal, der definerer egenskaberne for hver enkelt pixel i billedet. Yderligere er disse tal definerede inden for et spektrum af lagrings- og udtryksmuligheder.55 En af de måder, man forsøger at få indblik i algoritmernes billedanalyse, er ved at danne billeder af ’tværsnit’ i analyseprocessens lag. Dette kaldes feature visualization.56 De neurale netværk består som sagt af neuroner, og de responderer på forskellige elementer i billedet formidlet af de enkelte pixels ved at blive aktiveret eller ej. Hvert neuron har en vægtning, og de reagerer hver især på forskellige features, dvs. visuelle træk, som den enkelte pixel og dens nærmeste nabopixels danner. Det kan f.eks. være farver, kanter, kontraster, runde former, bølgelinjer mm. – en kunnen, de har oplært ved hjælp af træningssættet. Computeren ’ser’ m.a.o. ikke billedet men registrerer kun pixels og deres egenskaber defineret med tal. Computerens visuelle analyse er altså baseret på talberegninger, og derfor har processen ikke en visuel dimension på samme måde som denne menneskelige perception. Det betyder også, at feature visualizations er en form for fortolkning af, hvad der foregår, og de er ikke ’stillbilleder’. Disse visualiseringer består tit af delvist abstrakte elementer og delvist genkendelige delmotiver, og de illustrerer nogle af de træk, der har været afgørende for bedømmelsen af et billede. Muligvis identificerer computeren et stribemønster dannet af en grænseflade mellem pixels i hvid og rød-sort og konkluderer rigtigt, at det er en baseball. Men det betyder, at computeren definerer bolden i forhold til det pixelmønster, dens syninger danner, og ikke i sin helhed som figur mod grund.57 Alternativt bruger den elementer omkring bolden, f.eks. baggrundsfarven som i ulv-hund-eksemplet, til at definere forekomsten af baseball. Computeren arbejder sig altså systematisk igennem sæt eller udsnit af relationer i billedets data, hvori den forsøger at identificere træk, der samles til en fælles klassifikation. Disse computerevner kommer nok til at ændre sig meget de kommende år.
Feature visualization-billederne illustrerer, at algoritmerne arbejder med delmængder og relationer mellem mindre enheder i billedet. Dette er en markant anderledes måde at opfatte et billede på, end det menneskelige øje gør, hvor figurationer gestaltes, og effekter dannes i et samspil mellem den fysiske perception og hjernens fortolkning af impulserne.58 Hertil kommer receptionsæstetikkens gamle erkendelse, at den kultur og de forudsætninger, betragteren kommer med, påvirker sanseoplevelse og fortolkning af billedelementerne. Det betyder, at de visuelle tricks og greb, billedproducenter har anvendt i årtusinder for at påvirke den perceptuelle proces og snyde øjet med forskellige formål, ikke virker på samme måde i computerens visuelle analyse.59 F.eks. kan man som menneske opleve, at to farvefelter er vidt forskellige, da de omgivende farver påvirker oplevelsen, selvom computeren vil genkende dem som pixels med fuldstændig ens farve. I kunsten bliver øjet ofte snydt for at fremme oplevelsen af rum, dybde, størrelsesforhold, spænding, lys osv. Disse tricks registreres ikke på samme måde af computeren, samtidig med at den kan have vanskeligt ved at vurdere ambivalente fremstillinger. Det kan være tvetydig rumlig dybde eller skift i semantisk betydning alt efter, hvordan man identificerer enkeltdelene og deres samspil. Mens mennesket ofte nemt vil genkende et motiv som ’trist mand’ eller en harmonisk stemning i en abstrakt komposition, så har computeren ikke et følelsesmæssigt register, kunsten kan spille ind i og dermed medvirke til at samle og gestalte billederne alt efter den enkeltes erfaringsrum. Computeren er begrænset til de kategorier, vi giver den, eller som den selv danner ud fra materialet. Men det betyder så også, at den ikke (på samme måde) bliver påvirket af det triste blik fra manden eller af at synes, at abstrakt kunst er kedelig.
Den visuelle analyse
Computerens analyse fungerer anderledes, og det rejser en række spørgsmål, når man vil anvende computerens billedanalytiske evner til kunsthistoriske formål. Kan man bruge dens præcise måling af pixels, deres omfang og egenskaber, til noget relevant? Hvornår bliver man påvirket af illusoriske tricks, som computeren ikke påvirkes af – og omvendt, hvilke visuelle fænomener er vanskelige at håndtere for computeren? Og kan computerens måder at sammenligne strukturer i pixelsammensætninger og kompositioner anskueliggøre ligheder eller beslægtede træk, som er hinsides den menneskelige perceptions evner? Og helt basalt set kan man stadig spørge, hvilke visuelle strukturer fanger computerens opmærksomhed. Her har det vist sig, at ikke kun enkle træk som billedrammer dominerer i bedømmelsen, men også at computeren har visuelle præferencer, f.eks. er tekstur en dominerende faktor fremfor form i klassifikationerne.60
I 2018 opsummerede kunsthistoriker Peter Bell og computerspecialist Björn Ommer fem områder, hvor computeren kobler sig på den kunsthistorisk forankrede visuelle analyse: 1) søgning efter værkdupletter, 2) semantisk sammenligning af billedelementer på baggrund af objektgenkendelse, dvs. identifikation af billedelementer, 3) vurdering af forskelle mellem lignende værker ved hjælp af beregninger, 4) stilanalyse og 5) analyse af ligheder i store mængder billeder.61 Vi har i denne artikel præsenteret et eksempel på den femte type af visuel analyse, men man kan følge sporet af digitale forsøg i hvert af disse arbejdsområder, som har forskellige udviklingsgrader. Der findes andre lag i den visuelle analyse som metode. F.eks. er der udfordringer ved vekselvirkninger mellem visuelle og ikke-visuelle dimensioner af et værk eller i computerens interne proces, og som med tiden kan tilføjes denne liste. Som tidligere beskrevet er der flere grunde til, at det ikke er helt enkelt at oversætte den menneskelige billedanalyse til computeren. Derfor vil vi som det sidste knytte nogle ord til punkt to om objektgenkendelse, da denne proces også handler om den værdiladede relation mellem billede og ord, som kunsthistorie har arbejdet med i århundreder.
Objektgenkendelse: Ord og billede
Kunstnere og aktivister adresserer computerens ’blik’ ved på forskellig vis at snyde visuelle overvågningssystemer rundt omkring i verden. Paradoksalt nok kan denne søgen efter systemernes grænser være med til at forbedre deres performance. Det kan bl.a. handle om ansigtsgenkendelse. Generelt bliver systemer til objektgenkendelse (object detection) brugt kommercielt i mange sammenhænge, men det er også computerens svar på ikonografisk analyse, hvor billedelementer identificeres. Det handler altså om at sætte ord på billeder og klassificere korrekt. På det kunsthistoriske felt er man kommet længst med at få computeren til at genkende kristendommens ikonografi, som har en klar tekstlig referenceramme og er en grundlæggende del af klassificeringssystemet Iconclass, men i arbejdet med mange andre kunstneriske udtryk og motiver er resultaterne stadig af svingende kvalitet. Der er potentielt set rigtig meget at hente i anvendelsen af objektgenkendelse, men det kræver en god digitaliseringsproces og ofte rigtig meget arbejde at definere de mulige koblinger mellem ord og billeder. I kunsten kan form- og billedelementers betegnelser være ustabile og udefinérbare – endda polyvalente med vilje – og måske har de ikke engang en mimetisk referenceramme. Som sagt kan de enkelte billedelementer vekselvirke internt og fremtræde med forskellige betydninger. Der er med andre ord ikke altid et rigtigt svar, når computeren skal vejledes i, hvornår den rammer rigtigt i sin bedømmelse.
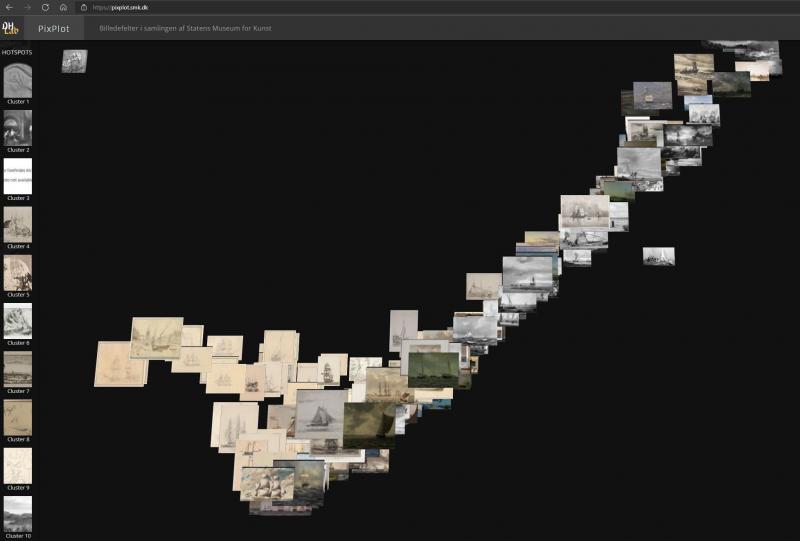
Problemet er grundlæggende set ikke af teknisk karakter men handler om, at semantisk annotering af billeder ikke er en værdifri eller objektiv proces. I sin afhandling om produktionen af digitale tidslinjer gengiver Olivia Vane en pointe fra et interview med en museumsansat. Vedkommende beretter, at institutionen tidligere i højere grad fik forespørgsler på værker efter kunstnernavne, mens forespørgslerne i dag oftere er tematisk betonede, f.eks. ’feminism’ eller ’black history’.62 Disse emner vil typisk være mindre anvendte i ældre indeksering og vil muligvis også kræve mere arbejde at identificere frem for f.eks. værker med maritimt motiv, hvor også computeren nemt kan ramme plet [Fig. 12]. Samme kritik rejser Alina Kühnl i sin artikel om racisme indbygget i Iconclass, og i samme tråd pointerer Iconclass-redaktør Hans Brandhorst, at hvis Iconclass skal bevare sin relevans, skal kategorierne og klassificeringen løbende revideres.63 De ændrede behov for indgange til værkerne peger på, at kunsthistoriefaget har brug for fleksible annoteringsredskaber, der ikke kun er manuelt betingede og dermed omkostningsfulde, men som i en vis grad kan automatiseres, så samtidige eller fremtidige behov for tilgængelighed af dokumentation og registrering af de visuelle aspekter via nøgletermer og emneindeksering kan følge den voksende mængde af værkdokumentation.
Perspektiver
Centre og afdelinger for digital humaniora er efterhånden en fast bestanddel på mange universiteter. De digitale humanister Sander Münster og Melissa Terras argumenterer for at etablere ’visuel digital humaniora’ for at markere, at der er brug for en særlig indsats i forhold til det visuelle.64 Samtidig er der tegn på, at flere facetter af den kunsthistoriske faglighed kan foldes ud i samspil med digitale metoder og redskaber i både historisk, tværfaglig og teoretisk retning. Den støt stigende mængde af digitale billeder af kunst og kulturgenstande i form af dokumentation, kunstneriske bearbejdninger og computerbaserede datavisualiseringer er både velkendt og nyt materiale for kunsthistorikerne at bearbejde. Ikke desto mindre stimulerer omfanget alene behovet og motivationen for at inddrage computeren og dens evne til at bearbejde de store mængder data. For at computeren effektivt og reflekteret kan blive inddraget i forhold til arbejdet med kuratering, formidling eller forskning, er det samtidig vigtigt, at fagfolk som kunsthistorikere melder ind, hvad der er brug for fra denne fagligheds perspektiv. Og ikke mindst at de giver feedback på udviklingen af – også halvfærdige – digitale redskaber samt deres funktionaliteter og begrænsninger. Ligeledes er det relevant at se på, hvordan andre fags studier og brug af de digitale billeder og redskaber griber direkte ind i fagets kerneaktiviteter såsom den visuelle analyse.
Opsummerende kan det siges, at den tidligere nævnte ’potentielt transformerende effekt’ af faget kan handle om, at de digitale metoder og redskaber bidrager til: 1) at det kunsthistoriske genstandsfelt udvides i kraft af datavisualiseringer og en større produktion af visuel dokumentation ifm. kunst og kultur, 2) at reaktualisere den visuelle analyse og diskussioner om det menneskelige blik versus maskinens, 3) at øge procesforståelse og -refleksion, 3) at øge omfanget og kvaliteten af samarbejdsformer og at give mulighed for en større grad af teambaseret forskning og 4) at understøtte tværfaglige samarbejder.
Disse perspektiver tager fokus væk fra diskussionen om, hvorvidt den digitale teknologi kan stå i stedet for de analoge kunsthistoriske arbejdsprocesser. De peger i stedet på forandringer og forventninger, som foregår og kommer til udtryk på humaniora og i samfundet. For selvom langtfra al kunsthistorisk forskning egner sig til at få et digitalt element integreret, så kan kulturændringer i forskningslandskabet på sigt få betydning for kunsthistoriefagets metodiske repertoire, pulje af visuel empiri og selvforståelse.65 Forandringerne kan implicere, at man som kunsthistoriker i højere grad skal investere tid og energi i at lave og dele procespapirer, uanset om der er et digitalt element eller ej. Det kan også handle om at dyrke evnen til at genkende datasæt i det kunsthistoriske materiale, som vil kunne bearbejdes af computeren, eller som vil kunne anvendes i samspil med andre fagligheder og deres ærinder. Eller at man ved, hvor det gælder om at være kritisk i brugen af computerbaserede metoder. Dette indebærer, at man opøver en forståelse for, hvilke standarder og krav datasættet skal opfylde, men også at man systematisk foretager erfaringsopsamling i forhold til, hvordan man etablerer et workflow mellem flere fagligheder. Ikke mindst drejer det sig om at være årvågen og have forestillingsevnen til at kunne identificere problemstillinger, der kan have kernefaglig kunsthistorisk relevans, men hvor man samtidig kan involvere andre fagfelters kompetencer for at styrke løsningen. Udfordringen er her at skabe en balance imellem de involverede fagfelter, da det ene forskningsfelts arbejde nemt kan få karakter af hjælpedisciplin for det andet.
Noter
Om forfatteren



